Python API (Intermediate Level)
If you are looking for beginner or advanced Python API, → Python API (Beginner Level) Python API (Advanced Level)
What is Time Complexity? How does it relate to this current API?
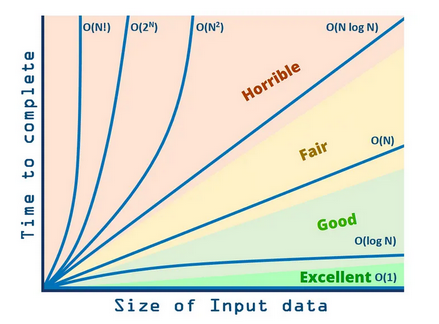
Time complexity is a measure of how the running time of an algorithm (operation on data - search for records, sorting, filtering) grows as the size of the input data (n) increases. It is typically expressed using Big O notation, which provides an upper bound or worst-case estimate of the algorithm's performance, independent of the specific machine or programming language used.
Key Concepts
- Not Actual Time: Time complexity doesn't measure the actual execution time in seconds, as that varies by hardware. Instead, it counts the number of elementary operations (steps) an algorithm performs.
- Rate of Growth: The primary focus is on the rate of growth of operations relative to the input size
(n). Constant factors and lower-order terms are ignored for large inputs because the dominant term determines how the algorithm scales. For example,O(n2 + n)is simplified toO(n2). - Worst-Case Analysis: Big O notation usually describes the worst-case scenario, which guarantees that the algorithm will never be slower than that upper bound.
We will see below how this API demonstrates these concepts in practice.
For Data Analysts, APIs are a direct line to real-time insights. They let you query data that isn't yet in the warehouse. You can connect APIs to BI tools for live, automated dashboards.
This bypasses stale data and accelerates your analysis. In short, APIs are the pipes that connect data sources to data consumers.
Project Overview
This Python Code improves on previous simple Employee Management API using the Python's FastAPI framework.
It allows a user to perform basic "CRUD" (Create, Read, Update, Delete) operations for employee records while persisting data efficiently
in a PostgreSQL database in place of in-memory storage to persist data across server restarts.
Below are the few main files of the project with code snippets. (github link for the complete project is given at the end of this page)
from contextlib import asynccontextmanager
from typing import List
from fastapi import FastAPI, Depends, HTTPException, status
from sqlalchemy.ext.asyncio import AsyncSession
from . import crud
from .database import get_session, create_db_and_tables
from .models import Employee, EmployeeCreate, EmployeeUpdate
# --- App Lifespan ---
@asynccontextmanager
async def lifespan(app: FastAPI):
"""Handles application startup and shutdown events."""
print("Starting up... creating database tables if they don't exist.")
await create_db_and_tables()
print("Startup complete.")
yield
print("Shutting down...")
# --- FastAPI App Instance ---
app = FastAPI(
title="Employee Management API",
description="API using FastAPI, PostgreSQL, and SQLModel with an organized structure.",
lifespan=lifespan
)
# --- API Endpoints ---
@app.get("/")
def read_root():
return {"message": "Welcome to the Employee Management API. Use 'emp_id' in routes like /employees/101"}
@app.post("/employees/", response_model=Employee, status_code=status.HTTP_201_CREATED)
async def add_new_employee(
employee_input: EmployeeCreate,
session: AsyncSession = Depends(get_session)
):
existing = await crud.get_employee_by_emp_id(session, employee_input.emp_id)
if existing:
raise HTTPException(
status_code=status.HTTP_409_CONFLICT,
detail=f"Employee business ID '{employee_input.emp_id}' already exists"
)
employee = await crud.create_employee(session, employee_input)
return employee
@app.get("/employees_all/", response_model=List[Employee])
async def read_all_employees(session: AsyncSession = Depends(get_session)):
return await crud.get_all_employees(session)
@app.get("/employees/{emp_id}", response_model=Employee)
async def read_employee_by_id(emp_id: int, session: AsyncSession = Depends(get_session)):
employee = await crud.get_employee_by_emp_id(session, emp_id)
if not employee:
raise HTTPException(status_code=404, detail=f"Employee with emp_id '{emp_id}' not found")
return employee
@app.put("/employees/{emp_id}", response_model=Employee)
async def update_employee_details(
emp_id: int,
updated_details: EmployeeUpdate,
session: AsyncSession = Depends(get_session)
):
db_employee = await crud.get_employee_by_emp_id(session, emp_id)
if db_employee is None:
raise HTTPException(status_code=404, detail=f"Employee with emp_id '{emp_id}' not found")
return await crud.update_employee(session, db_employee, updated_details)
@app.delete("/employees/{emp_id}", status_code=status.HTTP_204_NO_CONTENT)
async def remove_employee_by_id(emp_id: int, session: AsyncSession = Depends(get_session)):
employee_to_delete = await crud.get_employee_by_emp_id(session, emp_id)
if employee_to_delete is None:
raise HTTPException(status_code=404, detail=f"Employee with emp_id '{emp_id}' not found")
await crud.delete_employee(session, employee_to_delete)
return
import os
from dotenv import load_dotenv
from sqlmodel import SQLModel
from sqlalchemy.ext.asyncio import create_async_engine, AsyncSession, async_sessionmaker
# Load environment variables from the .env file
load_dotenv()
# Load the database URL from an environment variable.
# The application will fail to start if this is not set.
DATABASE_URL = os.getenv("DATABASE_URL")
if not DATABASE_URL:
raise ValueError("DATABASE_URL environment variable is not set")
# Load the database URL from an environment variable for security
# Defaulting to your local setup for convenience.
# DATABASE_URL = os.getenv("DATABASE_URL", "postgresql+asyncpg://postgres:$@localhost:5432/")
# Create the async engine
# echo=False in production for cleaner logs
engine = create_async_engine(DATABASE_URL, echo=True)
# Create a sessionmaker
async_session_maker = async_sessionmaker(engine, class_=AsyncSession, expire_on_commit=False)
async def create_db_and_tables():
"""Function to create database tables on startup."""
async with engine.begin() as conn:
await conn.run_sync(SQLModel.metadata.create_all)
# Dependency to get an async session for API endpoints
async def get_session():
"""Yields a new database session for a single request."""
async with async_session_maker() as session:
yield session
import uuid
from datetime import date
from typing import Optional
from sqlmodel import SQLModel, Field
# --- Database Model ---
# Represents the 'employee' table in the database
class Employee(SQLModel, table=True):
# 'id' is the internal unique database key (UUID/Primary Key)
id: Optional[uuid.UUID] = Field(default_factory=uuid.uuid4, primary_key=True)
# 'emp_id' is the user-assigned unique business ID (integer)
# index=True is the key to O(1) performance for lookups.
emp_id: int = Field(unique=True, index=True)
emp_name: str
city: str
country: str
emp_dob: date
# --- API Models (Pydantic) ---
# These define the shape of data for API input/output, providing validation.
class EmployeeCreate(SQLModel):
"""Model for creating a new employee."""
emp_id: int
emp_name: str
city: str
country: str
emp_dob: date
class EmployeeUpdate(SQLModel):
"""Model for updating an existing employee (all fields are optional)."""
emp_name: Optional[str] = None
city: Optional[str] = None
country: Optional[str] = None
emp_dob: Optional[date] = None
from typing import List, Optional
from sqlmodel import select, SQLModel
from sqlalchemy.ext.asyncio import AsyncSession
from .models import Employee, EmployeeCreate, EmployeeUpdate
async def get_employee_by_emp_id(session: AsyncSession, user_emp_id: int) -> Optional[Employee]:
"""
Helper to find an employee by emp_id using an indexed DB query (O(1) performance).
"""
statement = select(Employee).where(Employee.emp_id == user_emp_id)
result = await session.execute(statement)
return result.scalars().first()
async def get_all_employees(session: AsyncSession) -> List[Employee]:
"""
Retrieves all employees.
Note: For production, this should be paginated.
"""
statement = select(Employee)
results = await session.execute(statement)
return results.scalars().all()
async def create_employee(session: AsyncSession, employee_in: EmployeeCreate) -> Employee:
"""Creates a new employee record in the database."""
# Use .model_dump() to transfer data from the Pydantic 'Create' model
# to the SQLModel 'Employee' DB model.
employee_db = Employee.model_validate(employee_in)
session.add(employee_db)
await session.commit()
await session.refresh(employee_db)
return employee_db
async def update_employee(session: AsyncSession, db_employee: Employee, employee_in: EmployeeUpdate) -> Employee:
"""Updates an existing employee's record."""
# exclude_unset=True ensures we only update fields that were actually provided.
update_data = employee_in.model_dump(exclude_unset=True)
for key, value in update_data.items():
setattr(db_employee, key, value)
session.add(db_employee)
await session.commit()
await session.refresh(db_employee)
return db_employee
async def delete_employee(session: AsyncSession, db_employee: Employee):
"""Deletes an employee from the database."""
await session.delete(db_employee)
await session.commit()
return
# .env - Environment variables for the application
# Replace with your actual database credentials and a strong secret key.
DATABASE_URL="postgresql+asyncpg://<\username\>:<\password\>$@localhost:5432/<\database_name\>"
SECRET_KEY="a_strong_secret_key_that_is_long_and_random_and_not_commonly_used"
It is also built with a clean, separated architecture using a robust set of Python technologies:
- Backend Framework: FastAPI for its high performance, automatic documentation, and dependency injection system.
- Database Interaction: SQLModel, which combines Pydantic's data validation with SQLAlchemy's ORM capabilities for clear and type-safe database operations.
- Database: PostgreSQL, a powerful open-source relational database.
- Server: Uvicorn, a lightning-fast ASGI (Asynchronous Server Gateway Interface) server, to run the application.
The API is designed to be efficient, scalable, and maintainable by adhering to best practices in software design and security.
File Structure and Architecture
The project follows a "separation of concerns" principle, where different parts of the application logic are organized into distinct files and directories. This makes the codebase easier to understand, test, and expand.
api-V2/
├── .venv/ # Virtual environment for project dependencies
├── app/ # The main Python package for the application
│ ├── __init__.py # Makes 'app' a Python package
│ ├── main.py # API Layer: Defines endpoints and handles HTTP requests
│ ├── crud.py # Data Access Layer: Functions for database operations
│ ├── models.py # Data Definition Layer: Defines data structures
│ └── database.py # Database Connection Layer: Manages DB connection
├── .env # Contains environment variables and secrets
├── .gitignore # Specifies files for Git to ignore (like .env)
└── requirements.txt # Lists all Python package dependencies
Role of Each File
app/main.py: The entry point for all web requests. This file defines the API endpoints (e.g.,/employees/,/employees/{emp_id}), handles HTTP methods (GET,POST,PUT,DELETE), and uses FastAPI's dependency injection to get a database session. It acts as the "controller" that receives a request and calls the appropriate function to handle it.app/crud.py: The "CRUD" logic layer. All functions that interact directly with the database (querying, inserting, updating, deleting) are located here. This file keeps the database logic separate from the web routing logic inmain.py.app/models.py: Defines the shape of the data. It contains two types of models:- Database Model (
Employee): A SQLModel that represents the structure of theemployeetable in the database. - API Models (
EmployeeCreate,EmployeeUpdate): Pydantic models that define the expected JSON structure for incoming API requests. This separation is crucial for security and validation.
- Database Model (
app/database.py: Responsible for all database connection setup. It creates the database engine, manages sessions, and provides aget_sessiondependency for the rest of the application. It's also configured to load the database URL from the.envfile..env: A configuration file used to store sensitive data like database credentials and secret keys. It is explicitly excluded from version control via.gitignoreto prevent secrets from being exposed.requirements.txt: A list of all Python libraries needed for the project, ensuring a reproducible environment for any developer.
Time Complexity Analysis
The performance of an API is critical, and this application is designed for high efficiency on its most common operations.
O(1) - Constant Time Complexity (Excellent)
The following operations are extremely fast and their performance does not degrade as the number of employees grows:
GET /employees/{emp_id}(Read one employee)PUT /employees/{emp_id}(Update one employee)DELETE /employees/{emp_id}(Delete one employee)- The duplicate check inside
POST /employees/
Reason: All these operations rely on the get_employee_by_emp_id function, which performs a lookup using a WHERE clause on the emp_id column. Because the Employee model in models.py defines this field with index=True, the database maintains a B-Tree index. This allows it to find any employee by their ID almost instantly, without scanning the entire table.
O(n) - Linear Time Complexity (Area for Improvement)
GET /employees_all/(Read all employees)
Reason: This endpoint executes a SELECT query without a WHERE clause, forcing the database to read every single row (n) in the employee table. While acceptable for a small number of records, this endpoint will become slow and memory-intensive as the database grows. The standard solution is to implement pagination, allowing a client to request data in smaller, fixed-size chunks (e.g., ?limit=100&skip=200).
Security Analysis
Security is a multi-layered concern. This project implements several key security practices and has a clear path for further enhancement.
Secrets Management (Implemented)
.envFile: All sensitive data, including theDATABASE_URLand aSECRET_KEY, are stored in a.envfile, not hardcoded in the source code..gitignore: The.envfile is listed in.gitignore, preventing it from ever being committed to version control. This is the most critical step in protecting credentials.
Input Validation (Implemented)
- Pydantic Models: FastAPI uses the
EmployeeCreateandEmployeeUpdatemodels to automatically validate all incoming data. If a request contains data of the wrong type (e.g., a string foremp_id) or is missing required fields, it is immediately rejected with a422 Unprocessable Entityerror. This prevents malformed data from ever reaching the database logic.
Prevention of Mass Assignment Vulnerabilities (Implemented)
- By using a separate
EmployeeUpdatemodel that omits theemp_idfield, the API makes it impossible for a user to change an employee's business ID after it has been created. This is a crucial security feature that ensures the immutability of key identifiers.
How to Run This Code
- Code at GitHub: You can download the complete code from
Python API V.02. - Install dependencies: Open your terminal and install FastAPI and the Uvicorn server:
pip install fastapi "uvicorn[standard]" - Run the server: In the same terminal, run this command:
uvicorn main:app --reloadmain: The name of your file (main.py).app: The name of theFastAPI()object in your code.--reload: This makes the server restart automatically every time you save changes to the file. (This time the database will persist because its not an in-memory database.)
- View the API Docs: Open your browser and go to
http://127.0.0.1:8000/docs. You will see an interactive documentation page where you can test all your API endpoints.
If you are looking for more advanced Python API, → Python API (Beginner Level) Python API (Advanced Level)