Beginner Level - Data Extraction using Python
One if the right steps in working with python for data science or data analysis is
reading the data. Data comes in various formats, (structured and unstructured data)
For more serious & larger data extraction
Databases and BigData
, when data it starts becoming challenging because the data scope changes in terms of Volume / Velocity / Variety / Veracity;
But first let's begin with simple data extraction
Few of the common text formats are:
There are 2 ways of executing python code, one is plain python code (.py file),
other is jupyter notebook in an interactive way (.ipynb file).
I will be presenting Jupyter notebook example of connecting to various data file / formats:
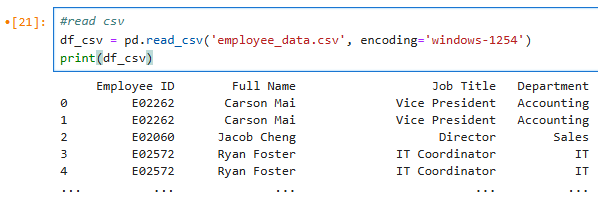
1. CSV - can be read using read_csv function;
## Jupyter Notebook
import pandas as pd
df_csv = pd.read_csv('employee_data.csv', encoding='windows-1254')
print(df_csv)
## Result is as below
If you are working with excel as .xls or .xlsx
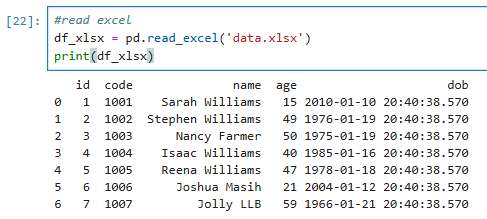
2. Excel - can be read using read_excel function;
## Jupyter Notebook
import pandas as pd
df_xlsx = pd.read_excel('data.xlsx')
print(df_xlsx)
## Result is as below
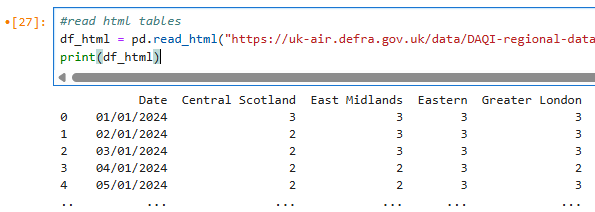
To read all tables found in the given HTML document
3. HTML Tables - can be read using read_html function;
This dataset is from UK Air Quality Pollution Index website Department of Environment Food & Rural Arrairs You'll need to install a package using (pip install lxml). It's a Powerful and Pythonic XML processing library.
## Jupyter Notebook
import pandas as pd
df_html = pd.read_html("https://uk-air.defra.gov.uk/data/DAQI-regional-data?regionIds%5B%5D=999&aggRegionId%5B%5D=999&datePreset=6&startDay=01&startMonth=01&startYear=2022&endDay=01&endMonth=01&endYear=2023&queryId=&action=step2&go=Next+")[0]
print(df_html)
## Result is as below
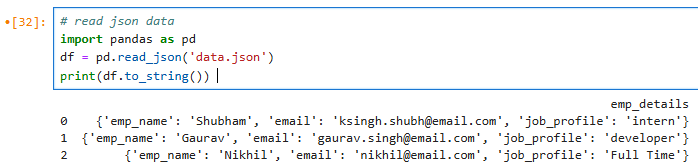
The most common data format today is JSON.
4. JSON - can be read using read_json function;
JSON is one of the most common format of data, while working on the Web or API's.
## Jupyter Notebook
import pandas as pd
df_json = pd.read_json("data.json")
print(df_json)
## Result is as below
Many times, we come across data in pdf tables.
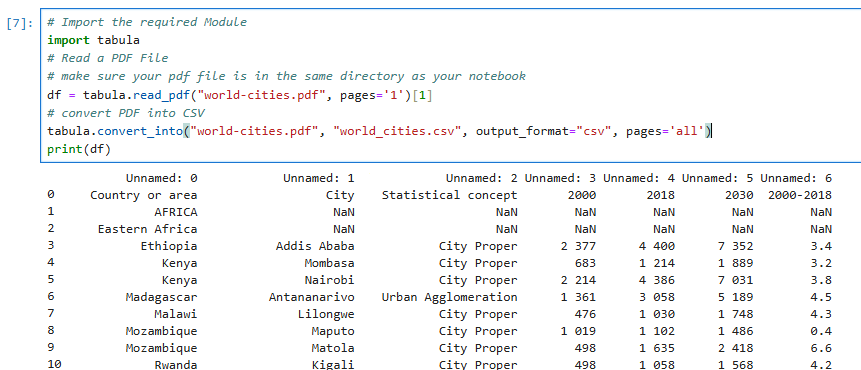
5. PDF - can be read using read_pdf function;
tabula-py is a simple Python wrapper of tabula-java, which can read table of PDF. You can read tables from PDF and convert them into pandas’ DataFrame. tabula-py also converts a PDF file into CSV/TSV/JSON file.
Since the data is read through multiple tables we provide [0] to start from beginning, or which ever table you intend to extract
* Requirements -
1. Java 8+
2. Python 3.9+
## Jupyter Notebook
# Import the required Tabula Module
import tabula
# Read a PDF File
# make sure your pdf file is in the same directory as your notebook
df = tabula.read_pdf("world-cities.pdf", pages='1')[1]
# convert PDF into CSV
tabula.convert_into("world-cities.pdf", "world_cities.csv", output_format="csv", pages='all')
print(df)
## Result is as below